YOLOv4 transfer learning for scanned document structure recognition
When you first hear about “YOLO”, you probably intuitively think about “You Only Live Once”. But it’s also the name of an object detection system called “You Only Look Once”.

As shown above, YOLO can detect different objects within an image and predict a label for each of them in a very short time (1–2 seconds for a high-resolution image on a P2 GPU). It is undoubtedly popular in the real-time object detection field. However, it’s rarely applied in the document structure or table detection domain. So far, I have only found one paper related to this topic. Given the promising result from the paper and YOLO’s generalization capability, I decided to implement the transfer learning of YOLOv4 for this task.
This article will give a brief introduction to YOLO and focus on the implementation of YOLOv4 transfer learning to detect scanned document structure using the Marmot dataset. Please be aware that any commercial use of the dataset must be permitted by Founder Apabi. The current article is only for research purposes.
A brief introduction to YOLO
The latest version YOLOv4, developed by Alexey Bochkovskiy, Chien-Yao Wang, and Hong-Yuan Mark Liao, was released in Apr. 2020. As the figure shows below, it achieved state-of-the-art performance compared with other models at the time, 12% faster and 10% more accurate than YOLOv3.

From a high level, it divides an input image into S x S grids. If the center of an object falls into a grid cell, this cell will be responsible for its classification. Each grid cell predicts a fixed number of bounding boxes. Eventually, only the box with the highest confidence score is used for training and prediction.

Conceptually the model is a CNN network. It first reduces the feature dimensions of input images using convolutional and pooling layers, and then pass the outputs to two fully connected layers for prediction of bounding boxes, confidence score, and the class label. The loss function’s design is what makes it different from traditional approaches, such as R-CNN and fast R-CNN.
If you want to learn more about the model, I highly recommend the resources in the reference.
Implementation of YOLOv4 custom training
Dataset Preparation
The Marmot dataset is composed of Chinese and English pages with 15 different labels. I used only the English dataset that contains 1,006 images and five labels: Table, TableBody, TableFootnote, TableCaption, Paragraph. The annotation data are in XML format.
I developed code to loop through each XML file and find the bounding box information for the target labels. The tricky part is to convert the original bounding box information, which is in hexadecimal format, to normalized values between 0 and 1 required by the YOLO model. To evaluate my conversion, I used Yolo_mark to annotate the same image and compare the coordinates values. If you run into trouble with OpenCV while compiling Yolo_mark, here is a post that helped me.
For each positive image, you need to generate a .txt file in the same directory with the same name. For negative images, you can include them in the same directory without .txt file. Each line in the file contains an object class id and the coordinates of that object.
<object-class> <x_center> <y_center> <width> <height>Object-class ranges from 0 to the total number of classes minus 1. In my case, it’s from 0 to 4 for five labels.
The four coordinates are values relative (between 0 and 1) to the total width and height of the image. Please pay special attention to the <x_center> <y_center>, as they are the center of the rectangle, not the top-left point. Below is an example of my train.txt file.
2 0.274538413 0.22350818 0.346147266 0.0254018459
1 0.275281816 0.45046899 0.365293325 0.3980142464
...Here is a sample code handling the data format conversion. For details, please review this git repo.
How to train your custom YOLOv4 model
Before starting, I highly recommend you go through the tutorial and the requirements on the official YOLO GitHub page. The following steps are conducted in the terminal on Linux.
- Git clone the repo.
git clone https://github.com/AlexeyAB/darknet.git2. Go to the darknet directory and change parameters in the Makefile. Set GPU, CUDNN, and OPENCV to 1 to accelerate the training process if you have GPU. Make sure your system has the right versions required by YOLOv4, and the CUDA and CUDNN file paths are correct. Then type the following command to compile the model.
cd darknet
make3. Create obj.data, obj.name, train.txt, test.txt and yolo-obj.cfg files following the instructions here. Adjust the parameters accordingly based on your needs. In my case, I chose 10,000 epochs for my training. The yolo-obj.cfg is an abstract skeleton of the YOLO model.
The obj.name contains the class labels and the sequence matters for prediction result.
Table
TableBody
TableCaption
TableFootnote
ParagraphThe obj.data includes the path of different file and folders
classes= 5
train = ./build/darknet/x64/data/train.txt
valid = ./build/darknet/x64/data/test.txt
names = ./build/darknet/x64/data/obj.names
backup = ./build/darknet/x64/backupTrain.txt and test.txt indicates the location of the images.
./build/darknet/x64/data/obj/10.1.1.6.2197_3.jpg
./build/darknet/x64/data/obj/10.1.1.36.2833_22.jpg
...4. Next, download the yolov4.weights, and then you can start to train the model with the following command line. Please adjust the file paths based on your current directory and the files directory.
./darknet detector train ./build/darknet/x64/data/obj.data ./build/darknet/x64/yolo-obj.cfg ./build/darknet/x64/yolov4.conv.137For every 100 iterations, the model will save the weights as yolo_obj_last.weight to the ./build/darknet/x64/backup folder. For every 1000 iterations, the model will save the weights as yolo-obj-xxxx.weights to the same folder.
You can always stop training and resume it using the latest weights.
./darknet detector train ./build/darknet/x64/data/obj.data ./build/darknet/x64/yolo-obj.cfg ./build/darknet/x64/backup/yolo-obj_last.weights5. Stop the training when you see that average loss 0.xxx avg no longer decreases at many iterations.
Model Evaluation
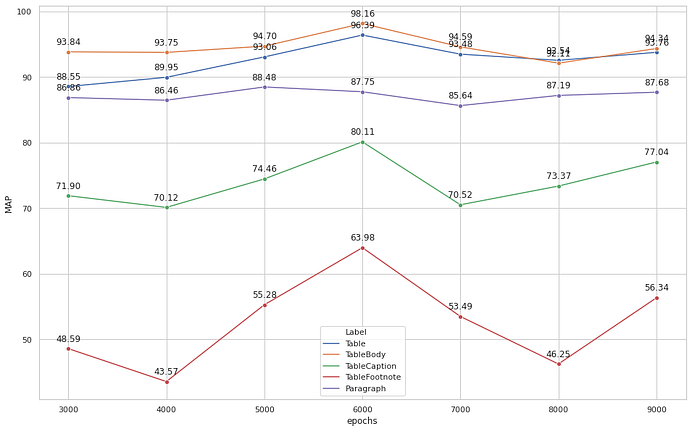
Here are my results for 9,000 epochs. As you can see, the model starts to overfit after 6,000 epochs.

MAP is the abbreviation for Mean Average Precision.
Let’s break down the performance by class labels on the validation dataset. Table, TableBody, Paragraph tend to have better accuracy than TableCaption and TableFootnote. Possible reasons could be that the latter two are smaller objects and have fewer training data than the rest. e.g., there are only 135 TableFootnote in the training data.
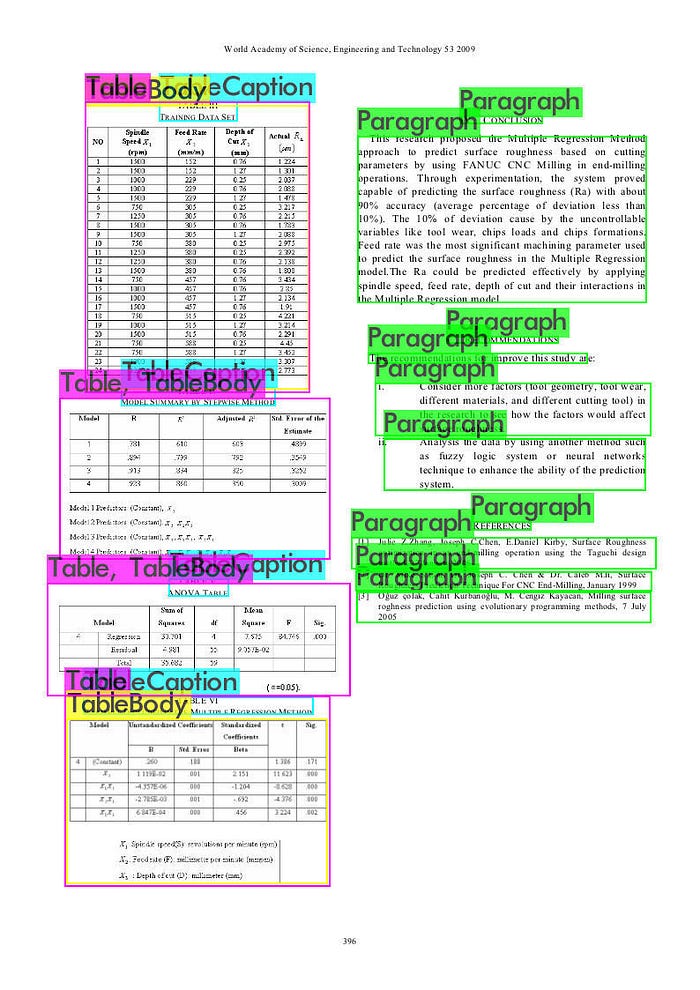
Model detection
Choose the weights based on your use case. Here I chose the weights of 6000 epochs since it achieves the highest score on the validation dataset. To make a prediction on a single image, run the following command.
./darknet detector test ./build/darknet/x64/data/obj.data ./build/darknet/x64/yolo-obj.cfg ./build/darknet/x64/backup/yolo-obj_6000.weightsTo process multiple images and save the results to a .txt file, you can use the following. Here ./custom_pred/custom_train.txt is the file that contains the paths of testing images, and ./custom_pred/custom_result.txt is the output file of the prediction result.
./darknet detector test ./build/darknet/x64/data/obj.data ./build/darknet/x64/yolo-obj.cfg ./build/darknet/x64/backup/yolo-obj_6000.weights -dont_show -ext_output < ./custom_pred/custom_train.txt > ./custom_pred/custom_result.txtHere is the visualization of the prediction result on a testing image.
Next Steps:
Here are some ideas to improve model performance:
- Set flag
random=1in the.cfg-file - For training and prediction, increase the network resolution in the
.cfg-file (height=608,width=608or any value multiple of 32) - Most importantly, use Yolo_mark to add more training data for the classes with few examples, such as TableFootnote.
- Use natural images as negatives data for the training.
References:
- https://github.com/AlexeyAB/darknet#yolo-v4-and-yolo-v3v2-for-windows-and-linux
- https://medium.com/@jonathan_hui/real-time-object-detection-with-yolo-yolov2-28b1b93e2088#:~:text=After%20removing%20the%20fully%20connected,is%20a%20multiple%20of%2032.
- https://medium.com/@jonathan_hui/yolov4-c9901eaa8e61
